Python Web Crowling
Back/Python 2022. 12. 21.웹 크롤링(Web Crowling)이란?
웹 페이지를 탐색하고 그 정보를 가져와 추출 및 가공하는 것즉, 웹(Web)에 있는 데이터를 수집해서 저장하는 일련의 과정
웹 크롤러(Web Crawler)란?
사용자가 보다 효율적으로 검색할 수 있도록 다운로드한 페이지를 인덱싱하는 검색 엔진에서 처리할 페이지를 복사하는 도구
빅데이터 개념 및 특성
디지털 환경에서 생성되는 수치, 문자, 이미지, 영상 데이터를 모두 포함하는 대규모 데이터
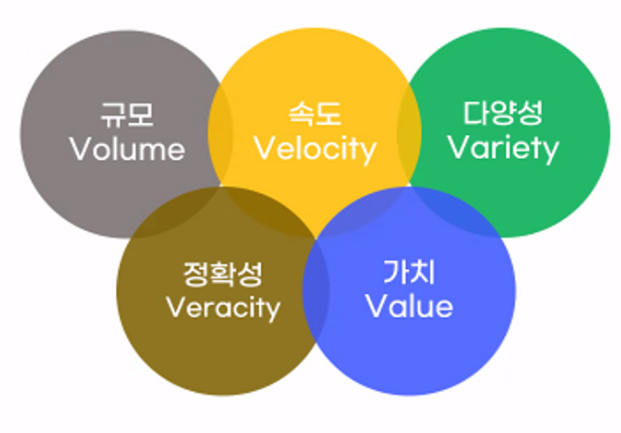

빅데이터 형태에 따른 구분 : 정형 데이터(Stuctured)
⦁ 데이터베이스의 정해진 규칙에 맞게 데이터가 들어간 데이터
ex) 관계DB, 스프레드시트, CSV…
빅데이터 형태에 따른 구분 : 반정형 데이터(Semi-Structured)

⦁ 고정된 필드에 저장된 데이터는 아니지만, 메타 데이터 및 스키마를 포함하는 데이터
ex) XML, HTML 텍스트, JSON …
빅데이터 형태에 따른 구분 : 반정형 데이터(Semi-Structured)

⦁ 고정된 필드에 저장되어 있지 않는 데이터
ex) ex) 소셜데이터(트위터, 페이스북), 영상, 이미지, 음성, 텍스트

웹 크롤러의 작동 방식

웹 크롤러의 작동 방식

Web Site의 HTML 문서 요청 → 크롤러를 이용하여 데이터 추출 → 추출한 데이터를 가공 및 저장
따라서 웹 크롤링을 위해서는 HTTP 구조에 대한 이해가 필요하다.
그럼 HTTP (HyperText Transfer Protocol)이란 무엇일까?
⦁ 하이퍼텍스트(HTML) 문서를 교환하기 위해 만들어진 protocol(통신 규약)
⦁ 웹상에서 네트워크로 서버끼리 통신을 할 때 어떠한 형식으로 통신할 지 규정해 놓은 “통신 형식” 혹은 “통신 구조”
⦁ 서버와 클라이언트 간 통신, 서버 간 통신에 사용
⦁ 통신방식 : 요청/응답(Request/Response)구조
HTTP 구조
1. HTTP요청 시에 헤더 정보가 딕셔너리(Key/Value) 형식으로 세팅
2. HTTP요청/응답 시에 대개 브라우저에서는 다음 헤더 설정
⦁ user-Agent : 브라우저의 정보
⦁ referer : 이전 페이지 URL(어떤 페이지를 거쳐서 왔는가?)
3. 크롤링을 할 때는 서비스에 따라 user-agent와 referer 설정 필요
ex) 네이버 검색, 네이버 웹툰 등
웹 크롤링 도구는 무엇인가?
Web Page가 어떤 구조(HTML)로 되어 있는가
어떻게(CSS Selectoir) 원하는 데이터를 추출할 것인가
requests
접근할 웹 페이지의 데이터를 요청/응답 받기 위한 라이브러리
메소드 기능설명 request.get(url) 원하는 웹 페이지를 요청/응답할 경우 request.get(url).status_code 요청에 대한 응답 상태 반환 request.get(url, headers={"UserAgent" : "" , "Referer" : "" ...}) 웹페이지 요청 시, 클라이언트 정보를 넘길 경우 request.get(url, params ={"key":"value","key":"value" ...}) 웹페이지 요청 시, 데이터를 넘길 경우(GET 방식)
BeautifulSoup
HTML문서에서 원하는 데이터를 추출하기 쉽게 해주는 라이브러리
⦁ 웹 페이지 내 데이터를 원하는 정보로 가공
lxml 시간적으로 덜 걸림
res = req.get(’http://www.naver.com’)
BeautifulSoup(res.text, 'lxml')
# res.text = data : request 라이브러리를 활용해서 응답 받은 데이터
# lxml = parser : 웹 페이지 내 데이터를 사용자가 원하는 형식으로 추출해 가공하는 프로그램
# (lxml, html.parser, html5lilb)Selenium
동적인 페이지를 제어하고 내용을 가져오기 위한 라이브러리
웹 자동화 테스트 도구 : 브라우저 제어 - 키보드 입력, 클릭, 스크롤, 이전 페이지 이동 등등
'Back > Python' 카테고리의 다른 글
| Python_Library_Test1 (0) | 2022.12.13 |
|---|

